Machine learning models strive to make accurate predictions by recognizing patterns in data. However, achieving the right balance between model complexity and generalization is essential. Overfitting occurs when a model becomes too complex, memorizing the training data but failing to generalize to new data.
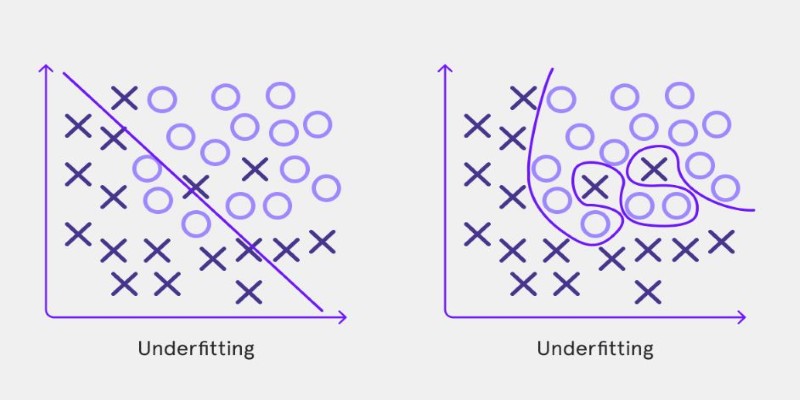
Underfitting, by contrast, results from a weak model lacking critical patterns and poor performance on training and test data. Knowing the differences between underfitting and overfitting and how to solve them is important for producing stable machine-learning models that accurately apply in real life.
Overfitting: When a Model Memorizes Instead of Learning
Overfitting happens when a machine learning model learns the noise and the details of the training data to an excessive extent. Rather than identifying the underlying patterns, it memorizes the data points and becomes very accurate on training data but unreliable on new, unseen data. This occurs when a model is too complex in proportion to the dataset, typically with too many features or parameters.
Think about studying for an exam by memorizing all the questions from a practice test rather than learning the concepts that they represent. You may ace the practice test but do poorly on new questions in the real exam. This is precisely what an overfit model does. It works incredibly well on the training data but cannot be generalized when presented with new data.
One major indicator of overfitting is a very large difference between training and test accuracy. When a model works well on the training dataset but performs badly on validation or test datasets, it is overfitting. This problem is prevalent when dealing with deep learning models, decision trees, or polynomial regression with high order.
Several strategies can help mitigate overfitting. Simplifying the model by reducing the number of features or parameters makes the model less complex and, therefore, less likely to fit all idiosyncratic details. Regularization methods like L1 (lasso) and L2 (ridge) regression include penalties for more complex models to make them select only important patterns. Increasing the size of the training dataset also helps, as more data provides a broader representation of real-world scenarios, reducing the likelihood of memorization. Additionally, techniques like dropout in neural networks randomly deactivate some neurons during training, preventing the model from becoming overly dependent on specific patterns.
Underfitting: When a Model Fails to Learn Enough
Underfitting is the opposite problem. It occurs when a model is too simple to capture the underlying patterns in the data, leading to poor performance on both training and test datasets. An underfit model has high bias, meaning it makes strong assumptions about the data, often resulting in overly simplistic predictions.
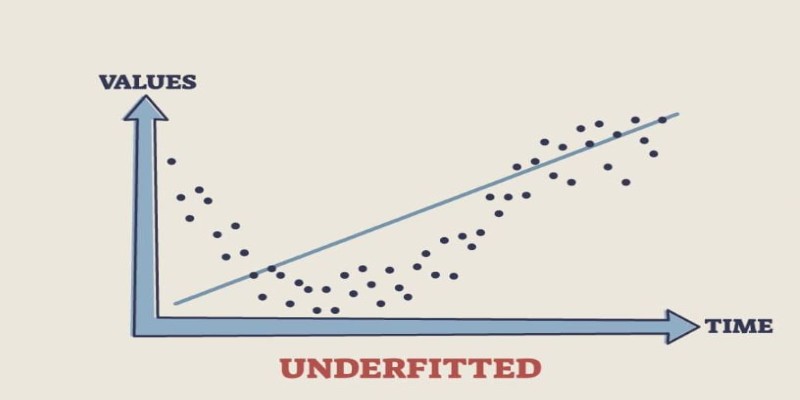
Think of trying to recognize handwriting but only paying attention to the overall shape of words without considering individual letters. If someone writes in a slightly different style, you might struggle to read it. This is how an underfit model behaves—it generalizes so much that it misses essential details needed for accurate predictions.
Underfitting is common when using overly simple algorithms, such as linear regression, for a dataset that requires a more complex approach. It can also happen if a model is trained for too few iterations, preventing it from learning the deeper relationships in the data.
Addressing underfitting requires increasing model complexity. Using more advanced algorithms, such as deep learning instead of simple regression, can help the model learn intricate patterns. Adding more relevant features to the dataset provides the model with additional information, allowing it to make better predictions. Increasing training time and fine-tuning hyperparameters, such as learning rates and batch sizes, can also improve performance.
Striking the Right Balance
The key challenge in machine learning is finding the right balance between overfitting and underfitting. A good model should neither be too simple nor too complex. Achieving this balance requires careful model selection, feature engineering, and tuning.
Cross-validation is one of the most effective techniques to ensure a model generalizes well. By splitting the dataset into multiple subsets and training the model on different combinations, cross-validation provides a more accurate assessment of performance. Another useful approach is early stopping, where training is halted when the model's performance on validation data stops improving, preventing excessive learning from training data.
Data preprocessing also plays a significant role in preventing both overfitting and underfitting. Normalizing numerical values, handling missing data, and selecting meaningful features can significantly improve model performance. Ensuring a diverse dataset with various real-world scenarios reduces the risk of a model relying too heavily on specific patterns.
Machine learning models require continuous refinement. Testing different algorithms, adjusting hyperparameters, and incorporating new data can improve their performance over time. By carefully monitoring training and validation metrics, it becomes easier to detect when a model is veering toward overfitting or underfitting and take corrective action.
Evaluating Model Performance: How to Detect Overfitting and Underfitting
Monitoring both training and validation performance is essential to detect overfitting or underfitting. Overfitting often results in a significant gap between high training accuracy and poor validation performance. If the model excels on training data but fails on new data, it's likely overfitting. In contrast, underfitting shows up as poor performance on both training and validation sets, indicating that the model hasn’t learned enough from the data.
Techniques like cross-validation, where the dataset is split into multiple subsets to train and validate the model repeatedly, provide a clearer picture of performance. Regular evaluation using loss functions and accuracy metrics on unseen data helps pinpoint when adjustments are necessary to improve generalization and prevent overfitting or underfitting.
Conclusion
Overfitting occurs when a model is too complex and memorizes training data, while underfitting happens when a model is too simple to capture meaningful patterns. Both result in poor performance. The goal is to balance these extremes, creating models that generalize well. Techniques like cross-validation, regularization, and feature engineering help achieve this balance. Continuous refinement and monitoring allow for the development of models that perform reliably in real-world scenarios, improving accuracy and efficiency over time.