In today's world of big data, businesses need fast and reliable ways to process enormous amounts of information. Hadoop and Spark are two of the most popular frameworks for handling such tasks, but they each have their strengths. While Hadoop is known for its ability to store and process massive datasets across multiple machines, Spark takes it a step further by offering faster, in-memory processing.
Whether you’re dealing with batch processing or real-time data, understanding the key differences between these two technologies is essential for choosing the right tool to power your data-driven decisions.
Understanding Hadoop
Hadoop was one of the earliest innovations in big data processing. It was created by the Apache Software Foundation and brought a method of storing and analyzing large volumes of data on several machines. The framework is based on the Hadoop Distributed File System (HDFS), which splits large files into smaller pieces and stores them on various nodes in a cluster. This makes it possible for Hadoop to process petabytes of data efficiently, and thus, it is the go-to tool for batch processing.
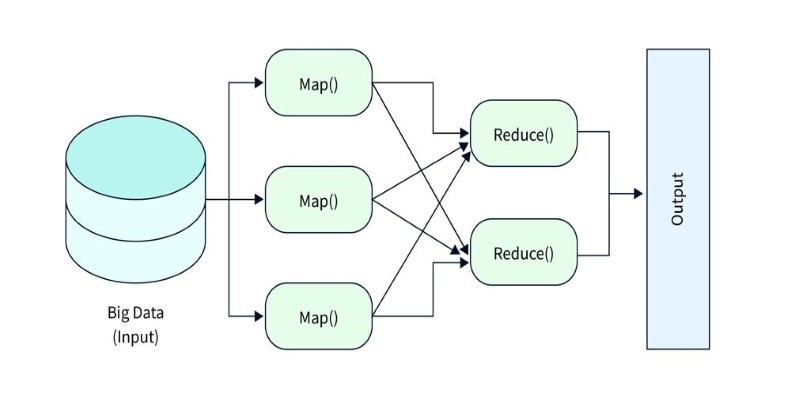
The essence of Hadoop is its MapReduce programming model. MapReduce breaks down tasks into smaller sub-tasks, processes them in parallel, and then aggregates the results. Although this process is powerful enough for big processing, it isn't perfect. The largest criticism is speed. Because Hadoop reads and writes to disk with each step in processing, latency is added in, which disqualifies Hadoop from handling real-time systems. Despite this, Hadoop remains a strong contender for storing and managing massive datasets, particularly when cost-effectiveness and reliability are top priorities.
The Rise of Spark
Apache Spark came out as a reaction to Hadoop limitations, specifically speed. It was designed to handle data in memory so that disk reads and writes would not be so common. This change of architecture makes Spark much faster than Hadoop's MapReduce. Benchmarking has demonstrated that Spark is up to 100 times as fast for some workloads. In contrast to Hadoop, which is batch-oriented, Spark can handle several workloads, such as real-time data streams, interactive queries, and machine learning.

Spark's power comes from its Resilient Distributed Dataset (RDD) abstraction. RDDs allow Spark to distribute data across a cluster while maintaining fault tolerance. If a node fails, Spark can recompute lost data without restarting the entire process. This feature makes it more flexible and efficient than traditional Hadoop-based batch processing. Additionally, Spark integrates with machine learning libraries, graph processing, and SQL-based queries, expanding its use cases beyond simple data storage and retrieval.
Key Differences and Use Cases
The primary distinction between Hadoop and Spark lies in their design and how they handle data. Both frameworks have their strengths, but they cater to different use cases and requirements.
Data Processing Speed
Hadoop processes data in batches and writes it to disk after each operation, leading to latency. This can be slower for complex jobs. On the other hand, Spark performs in-memory computing, keeping data in RAM during processing. This results in faster data analysis, often up to 100 times quicker than Hadoop for certain tasks. Spark's speed makes it ideal for real-time analytics, machine learning models, and applications where immediate insights are essential, while Hadoop’s slower pace suits batch processing jobs.
Storage and Scalability
Hadoop's HDFS (Hadoop Distributed File System) is designed for large-scale storage, capable of handling petabytes of data across multiple nodes. It efficiently stores both structured and unstructured data, making it well-suited for massive, long-term storage needs. Spark, by contrast, doesn't have a storage system and relies on external systems like HDFS or S3 for data storage. While Spark is scalable, Hadoop remains the more reliable solution for organizations that need to store large datasets over time, ensuring easy retrieval and processing.
Use Cases for Hadoop
Hadoop is excellent for use cases that involve large datasets, especially when real-time results aren't critical. It's ideal for log processing, where analyzing server or application logs can be done in batches without delay. Hadoop also excels in data warehousing by managing and processing huge volumes of historical data. ETL (Extract, Transform, Load) pipelines are another common Hadoop use case, as they can efficiently extract data, transform it, and load it into databases for further analysis without real-time constraints.
Use Cases for Spark

Spark is ideal for real-time processing and fast insights. It’s often used for real-time analytics, such as fraud detection systems or recommendation engines, where speed is crucial. Machine learning benefits from Spark’s built-in MLlib, enabling scalable data analysis and model development. Additionally, streaming data processing with Spark Streaming makes it perfect for analyzing live data from sources like social media, sensors, and IoT devices. Spark's flexibility and speed allow it to handle applications that need immediate results and iterative data processing.
Integration and Ecosystem
Hadoop’s ecosystem includes tools like Hive for querying, Pig for scripting, and HBase for NoSQL storage. These integrate seamlessly for large-scale batch processing and data management. Spark, while not a storage solution, is highly adaptable and can integrate with Hadoop’s ecosystem. Spark’s flexible API support for Java, Python, Scala, and R enables developers to work with the framework in the language of their choice. The ability to use both Hadoop and Spark together allows businesses to leverage Hadoop’s storage and Spark’s speed for more dynamic, powerful data workflows.
Conclusion
The choice between Hadoop and Spark depends on an organization's needs. Hadoop offers a cost-effective solution for storage and batch processing, making it ideal for long-term data management. Spark, with its in-memory processing, provides faster analytics, making it better suited for real-time applications. While Spark outperforms Hadoop in speed and flexibility, its higher hardware demands can be a limitation. Often, the best strategy is to use both together—leveraging Hadoop’s storage capabilities with Spark’s analytics power. Ultimately, the decision hinges on the scale, speed, and budget considerations of the data-driven tasks at hand.