Data fuels the modern world, shaping industries, decision-making, and artificial intelligence. But real-world data isn't always easy to obtain. Privacy concerns, limited availability, and bias all create obstacles. That's where synthetic data steps in—a powerful alternative that mimics real data without exposing sensitive information.
While synthetic data is created by computer algorithms instead of being gathered from actual events, it may also be extremely realistic and useful. From developing AI models to improving research, the technology is revolutionizing sectors in ways that would not have been feasible using conventional datasets alone.
Understanding Synthetic Data
Synthetic data is data that is artificially generated instead of being collected from actual sources. It captures the patterns and statistical characteristics of real data and can be employed for testing, training, and analysis. Unlike anonymized data, which de-identifies personal information from actual datasets, synthetic data is completely made up. This makes it a perfect fit for situations where privacy, security, or data availability are issues.
Synthetic data generation requires sophisticated methods like deep learning, probabilistic modeling, and rule-based simulation. Data scientists use these to build realistic but simulated datasets that behave like authentic ones. Mimicking financial activities, healthcare information, or consumer behavior, synthetic data is a moral and cost-effective solution over the use of actual user data.
One of its main benefits is flexibility. Conventional data collection has limitations—either by privacy legislation, sample size constraints, or ownership of the data. With synthetic data, companies and researchers can create any amount of information in accordance with unique requirements without legal or ethical constraints. It eliminates the danger of revealing actual individuals without compromising statistical accuracy.
How Synthetic Data Is Created?
There isn’t just one way to generate synthetic data. Different methods cater to different needs, ensuring that the artificial data remains useful and reliable. One common approach is statistical modeling, where historical data is analyzed to produce new data points that follow the same distribution. This method ensures that the synthetic dataset retains the characteristics of the original while avoiding exact duplication.

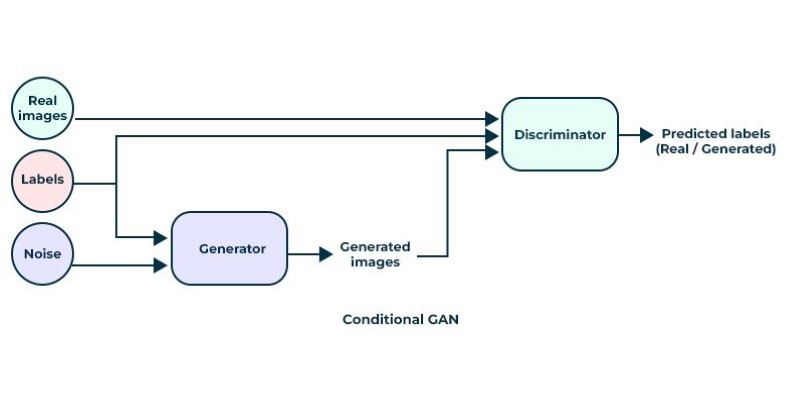
Another powerful technique involves generative adversarial networks (GANs). GANs use two competing neural networks—one that generates data and another that evaluates its authenticity. Over time, the generator improves until the synthetic data becomes nearly indistinguishable from real-world information. This method is widely used in fields such as computer vision and healthcare, where realistic data is crucial for AI training.
Simulation-based generation is also a popular approach. This method relies on predefined rules to create datasets that reflect possible real-world scenarios. For example, in autonomous vehicle testing, synthetic environments are created to simulate various road conditions, traffic patterns, and weather effects. This allows self-driving cars to be trained in millions of different situations without ever needing to hit the road.
Though synthetic data can be remarkably accurate, its quality depends on how well it reflects the original dataset. Poorly generated synthetic data can introduce biases or inaccuracies, leading to flawed outcomes. This is why organizations must carefully validate synthetic datasets before using them in critical applications.
The Role of Synthetic Data in AI and Industry
AI systems require vast amounts of data to function effectively, but real-world data is often limited, sensitive, or difficult to access. Synthetic data offers a scalable, customizable alternative, allowing industries to overcome data constraints while ensuring privacy and security.
In healthcare, synthetic patient data is helping train AI models for disease diagnosis. Medical records are highly sensitive and regulated, making real data difficult to use. By generating artificial yet realistic datasets, researchers can develop advanced diagnostic tools, predictive medicine models, and drug discovery techniques without privacy concerns.
The financial sector also benefits from synthetic data. Fraud detection, risk assessment, and customer behavior analytics require extensive datasets. Since financial transactions contain sensitive details, synthetic alternatives allow banks and institutions to refine AI models without exposing real user data.
Autonomous systems, such as self-driving cars and robotics, also rely on synthetic data. Real-world driving data is expensive and time-consuming to collect, but synthetic road environments can simulate traffic, weather, and hazards. This accelerates AI training, improving safety and efficiency in autonomous technology development.
Retail and e-commerce businesses use synthetic data to model customer interactions, product preferences, and purchasing behaviors. This enhances recommendation engines, optimizes marketing strategies, and improves customer experience—all without requiring vast amounts of real consumer data.
Despite its advantages, synthetic data isn’t flawless. If poorly generated, it may fail to capture real-world complexity, leading to inaccurate AI models. Ensuring diversity, accuracy, and bias-free datasets remains a challenge, but with continuous advancements, synthetic data is proving to be a game-changer across industries.
The Future of Synthetic Data
As AI continues to evolve, synthetic data is set to become even more important. Its ability to provide safe, scalable, and flexible datasets makes it a valuable asset in research, development, and training. With advancements in machine learning, synthetic data is expected to become more sophisticated, capturing even the most intricate details of real-world data.

Regulatory frameworks may also shape how synthetic data is used. Governments and organizations are exploring guidelines to ensure synthetic data meets ethical and accuracy standards. While synthetic data can help overcome privacy concerns, it must still be monitored to prevent unintended biases and misuse.
Conclusion
Synthetic data is transforming how industries handle data collection and AI training. It provides a scalable, privacy-friendly solution to data limitations, benefiting fields like healthcare, finance, and autonomous systems. As technology advances, synthetic data will play a growing role in AI development, ensuring innovation without compromising security. By enabling realistic yet artificial datasets, synthetic data bridges the gap between data scarcity and technological progress. While challenges like bias and accuracy remain, its potential is undeniable. As industries adopt this technology, the future of AI will be powered not just by real-world data but by synthetic data as well.